
Indian languages, comprising more than 100 languages, is the set of all languages that are spoken in the Indian subcontinent. It includes languages like Hindi and Bengali, which are some of the most widely spoken languages across the world. In total, Indian languages are widely spoken by more than a billion speakers. They include 8 out of the top 20 most spoken languages and have 30 languages with more than a million speakers.
The Problem
Indian languages, though being widely spoken, still has a poorly developed NLP ecosystem. There is a growing population of users consuming Indian language content (print, digital, government and businesses). However, the current state of NLP severely restricts both research and development of tools for Indian languages.
Indian languages are also very diverse, spanning 4 major language families, the major ones being the Indo-Aryan and Dravidian families which are spoken by 96% of the population in India. They also have various different linguistic properties than English, for example, they follow subject-object-verb word ordering, are morphologically rich, and allow free word ordering. All the above things also make Indian languages an exciting and important area for NLP research which can help improve our understanding of human languages in general.
As we later argue, the progress on NLP for Indian languages has been constrained by the unavailability of large scale datasets and some essential NLP models. Our project was set out with the aim of developing these core resources for Indian languages which can simplify the development of a wide variety of end-user tasks as well provide a starting ground to the researchers who want to work on Indian languages.
Building IndicNLP
Before presenting our work on IndicNLP, we introduce the reader to the following important concepts in NLP. In the following sections, we use the term Indic languages to refer to all the Indian languages and likewise, IndicNLP to refer to NLP on them.
Word Embeddings and Language Models: As a first step in solving most NLP tasks, the input text is encoded into semantic vectors, using neural models, which are then further processed depending on what the task is. In the case of the text being word, we use what are called as word embedding models, which basically map every word to a meaningful vector. Recent developments in NLP have introduced large-scale transformer-based language models (ULMFiT, BERT etc.) that can encode entire text into vectors at once. Both of these word-level and text-level encoding have been shown to give good results for a wide variety of downstream tasks. Language models also have an advantage that they can be used to solve many different tasks with only a small modification, as Fig 1 shows.
Datasets: Modern techniques in NLP leveraging deep learning rely on large-scale datasets for training and evaluation. A monolingual corpora (plain, unlabeled text) can be used in training many unsupervised models including language models, translation models and so on. While we can use labelled datasets for many end-tasks like text classification, semantic similarity etc. As a first step towards levelling up NLP for Indian languages, we needed to create these datasets for all the major Indian languages.
Benchmarks: Once we have the models for Indian languages, we need a way to gauge its performance. For this purpose, we need benchmarks, which is a set of wide variety of tasks that cover different aspects of evaluation. In case of language models, a good benchmark needs to be able to assess language understanding across various dimensions like syntax understanding, knowledge, logical capability etc.
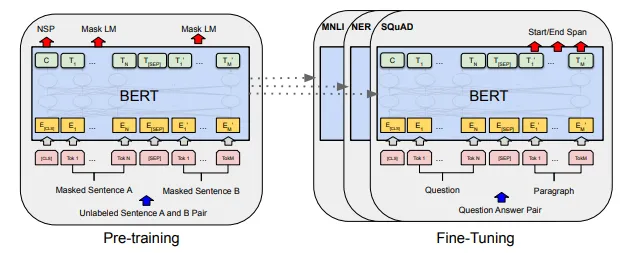
Figure 1: The BERT model is pre-trained on unlabeled text first (on the left) and then used for a downstream task (on the right). A pre-trained BERT language model has been shown to perform well on range of downstream tasks even with small task-specific data
Motivated by the above concepts, we built a collection of foundational resources for language processing, which we call IndicNLPSuite. IndicNLPSuite consists of a large-scale monolingual corpora IndicCorp, a pre-trained language model IndicBERT, pretrained word-embeddings IndicFT and a general natural language understanding benchmark IndicGLUE. We cover 12 major Indian languages in our work: Assamese, Bengali, English, Gujarati, Hindi, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, Telugu. Below are more details about each of them:
-
IndicCorp: A lot of NLP models require a large amount of training data, making it difficult for them to work for Indic languages because of their lack of datasets. In this project, we developed a large-scale monolingual corpora by intensively crawling the web. The corpora that we built has a total of 8.9 billion tokens and covers 12 major Indian languages. It has been developed by discovering and scraping thousands of web sources - primarily news, magazines and books, over a duration of several months. IndicCorp is now one of the largest publicly-available corpora for Indian languages. We also used it to train our released models which have obtained state-of-the-art performance on many tasks.
-
IndicBERT: IndicBERT is a multilingual ALBERT model trained on IndicCorp, covering 12 major Indian languages: It can be used for performing a wide variety of NLP tasks like sentiment analysis, common-sense reasoning, question answering etc. on Indian languages. IndicBERT has much fewer parameters than other public models like mBERT and XLM-R while it still manages to give state of the art performance on several tasks.
-
IndicFT: IndicFT is a word embedding model obtained by pre-training fastText on IndicCorp. We chose fastText as our underlying word embedding model because it is subword-aware, thus making it particularly well-suited for Indian languages due to their highly agglutinative morphology.
-
IndicGLUE: To thoroughly evaluate language models on Indian languages, we need a robust natural language understanding benchmark consisting of a wide variety of tasks and covering all the Indian languages. IndicGLUE is a a benchmark that we propose. Such benchmarks exist for languages like English, French and Chinese but IndicGLUE is the first attempt at creating a benchmark for Indian languages. Our goal is to provide a benchmark that can measure performance on different dimensions of NLU capabilities as well as measure performance on each of the 12 Indian languages.
Comparisons and Results
We train our models on IndicCorp and then evaluate them on the IndicGLUE benchmark. All the resources that we have built as part of IndicNLPSuite have shown some promising results, although there is still a lot of room for improvement. IndicCorp, our monolingual corpora is currently the largest publicly-available corpora for Indian languages with an average 9-fold increase in size over OSCAR, which was previously the largest corpora for Indian languages. IndicBERT, even after being much smaller in size, shows comparable and, in some cases, even better performance than other large-scale models. We obtain similar results for IndicFT. For a more detailed report of the results, please go through our paper.
Societal Impact
We believe that the resources we have built can accelerate both research and development around Indian languages. This work will also help in democratizing NLP. So far, the NLP technology has been useful only for the English-speaking population, but now it will reach the rest of the population as well. We are also expecting many new softwares and digital tools for Indian languages to come up in the near future, based on our work, which will not only bring NLP technology to the masses, but also create more business and economic opportunities in rural areas where regional languages flourish. From the research perspective, it also opens up several new problems about languages to the researchers. Our work provides a good starting ground for creating models and evaluating performance on Indian languages. Analyzing and studying Indian languages can help create models that better handle linguistic features found in Indian languages as well as use them to create better multilingual models that can understand and transfer knowledge across multiple languages.
Our Team
Our work was carried out as part of the AI4Bharat initiative. AI4Bharat is non-profit organization aimed at solving India-specifc problems using the AI technology. Our project has members from IIT Madras, One Fourth Labs and Microsoft Search Technology Center India.
Project Page
Reference
Kakwani, D., Kunchukuttan, A., Golla, S., Gokul, N. C., Bhattacharyya, A., Khapra, M. M., & Kumar, P. (2020). IndicNLPSuite: Monolingual Corpora, Evaluation Benchmarks and Pre-trained Multilingual Language Models for Indian Language. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings (pp. 4948-4961).
GitHub
Datasets
Media coverage
- IIT Madras faculty develop AI to process text in 11 Indian languages - The New Indian Express
- IIT-Madras faculty develop AI models to process text in 11 Indian regional languages - Hindustan Times
- IIT Madras faculty develop AI models to process text in 11 Indian regional languages - edexLIVE
Keywords
NLP, Deep Learning, Indian languages, indicnlp, multilingual NLP, BERT, ALBERT, FastText, word embeddings, language models, monolingual corpora, datasets